Trước khi đề cập tới NGC ( Next Graphics Core ) chúng ta hãy đề cập tới những gì đã diễn ra trong thế giới đồ họa trước đó .
Trước khi đề cập tới NGC ( Next Graphics Core ) chúng ta hãy đề cập tới những gì đã diễn ra trong thế giới đồ họa trước đó .Lịch sử VLIW và đồ họa
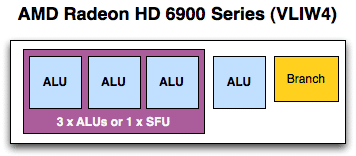
Bộ phận cơ bản thiết kế trước kia của AMD là SP ( Stream Processor ) hay còn được gọi là SPU . Trong những thiết kế AMD mới khác Cayman (6900) , là thiết kế VLIW5 (Very Long Instruction Word 5 ) ; Cayman là NLIW4 .
Đúng như tên gọi của nó , mỗi SP có từ 5 hoặc 4 bộ phận toán học cơ bản , mà AMD gọi là lõi Radeon , thực hiện những lệnh riêng song song với nhau . Những lõi Radeon là những thanh ghi ( Register ) , bộ phận rẽ nhánh ( Branch Unit ) và những bộ phận chức năng riêng biệt cần thiết để hình thành lên một SP đầy đủ .
Thiết kế VLIW có hoạt động nổi trội để thực hiện nhiều phép toán trong cùng nhiệm vụ song song với nhau bằng cách ngắt nó thành những nhóm nhỏ hơn gọi là những Wavefront . Trong trường hợp của AMD , một Wavefront là một nhóm 64 điểm ánh / giá trị ( Pixel / Value ) và danh sách lệnh để thực hiện .
Lý tưởng nhất , trong Wavefront một nhóm 4 hoặc 5 lệnh sẽ được gửi tới và hoàn toàn độc lập với nhau , cho phép mỗi lõi Radeon thực thi cùng một lúc . Tuy nhiên khi những lệnh phụ thuộc vào nhau được chuyển tới , trong đó có vài lệnh lại liên quan tới nhau và tệ hơn cả là chỉ có một lệnh đơn lẻ thì thiết kế VLIW sẽ không đạt được hiệu suất làm việc một cách hoàn hảo và điều đó lại thường xuyên diễn ra trong các ứng dụng thông thường chứ không phải các ứng dụng đồ họa hoặc trong Game .
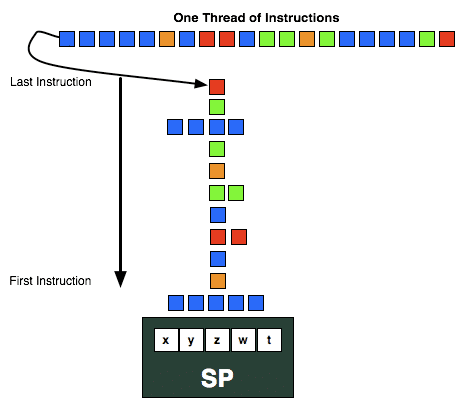
Hình trên ví dụ diễn tả dòng lệnh , cho thấy thiết kế VLIW chỉ thuận lợi nếu như có nhiều 4 hoặc 5 dãy lệnh độc lập với nhau .
Việc dùng VLIW có mặt trong những GPU DirectX 9 đầu tiên của AMD ( R300 ( Radeon 9700 Series ) . để phục vụ các công việc chuyên dụng liên quan tới xử lí đồ họa .
Khi chuyển sang cấu trúc những Shader hợp nhất trong DirectX 10 trong R600 ( Radeon HD 2900 ) , AMD vẫn giữ thiết kế VLIW5 bởi vì khi ấy thị trường Game vẫn còn DirectX 9 và dùng nhiều những câu lệnh như vậy . Nhưng những Game mới và các chương trình GPGPU thì thiết kế VLIW lại không đạt hiệu quả . AMD đã phải nghiên cứu đưa ra Cayman với chương trình Shader trung bình chỉ dùng 3 hoặc 4 trong 5 lõi Radeon . Việc rút gọn từ VLIW5 thành VLIW4 vẫn còn đang được sử dụng .
Cuối cùng thì không có cài gì tồn tại được mãi mãi mà chỉ khi nào thay đổi mà thôi .
Hiện tại không phải chỉ là Game , người ta tính toán làm thế nào để tận dụng sức mạnh của GPU trong những công việc thông thường , khi ấy cấu trúc GPU phải biến đổi theo để đáp ứng yêu cầu như vậy .
Trên thực tế NVIDIA đã đi theo hướng này từ cấu trúc Fermi .
NGC mới của AMD kết hợp VLIW với SIMD
Thiết kế VLIW rất tuyệt vời để tín toán đồ họa nhưng lại không phù hợp cho các tính toán thông thường khác . Tuy nhiên AMD cũng phát triển Fusion dùng GPU tích hợp với lõi CPU trên cùng một khuôn để kết hợp trong những công việc tính toán nhưng lõi x86 của AMD kém hiệu quả khiến cho tương lai của AMD không rõ ràng .
Với NGC mới của AMD đó là sự kết hợp giữa VLIW với thiết kế SIMD non-VLIW . SIMD được viết tắt từ – Single Instruction , Multiple Data – và được dùng trong thiết kế của bộ vi xử lí . Về mặt nguyên tắc đó là hai vấn đề tương tự nhau , chạy nhiều thứ song song với nhau nhưng khác nhau khi thực hiện . Để cho dễ hiểu VLIW để phục vụ cho những nhiệm vụ tính toán như đồ họa ILP (Instruction Level Parallelism ) , còn SIMD non-VLIW ưu tiên cho những nhiệm vụ tính toán thông thường TLP ( Thread Level Parallelism ) .
Cũng không cần đi sâu tìm hiểu sự khác nhau giữa VLIW và SIMD non-VLIW chỉ cần nhớ một cách đơn giản đó là VLIW rất kém khi sử dụng những ứng dụng thông thường dựa trên tính toán của GPU và AMD đã sửa chữa nó bằng cách đưa thêm SIMD non-VLIW
Tuy nhiên VLIW sống và chết dựa vào trình biên dịch ( Compiler ) và vấn đề ở đây rất khó để hỗ trợ những ngôn ngữ mở rộng gây khó khăn cho các nhà phát triển . Sự phức tạp của VLIW rất khó để tối ưu mã biên dịch , nhưng nên nhớ chúng ta đang nói tới các ứng dụng tính toán thông thường chứ không liên quan tới đồ họa hoặc các ứng dụng chuyên dụng nào đó .
AMD đã cung cấp ví dụ sau khi biên dịch để chạy với thiết kế VLIW và biên dịch mới cho NGC .
VLIW
// Registers r0 contains "a", r1 contains "b"// Value is returned in r200 ALU_PUSH_BEFORE 1 x: PREDGT ____, R0.x, R1.x UPDATE_EXEC_MASK UPDATE PRED01 JUMP ADDR(3)02 ALU 2 x: SUB ____, R0.x, R1.x 3 x: MUL_e R2.x, PV2.x, R0.x03 ELSE POP_CNT(1) ADDR(5)04 ALU_POP_AFTER 4 x: SUB ____, R1.x, R0.x 5 x: MUL_e R2.x, PV4.x, R1.x05 POP(1) ADDR(6)Non-VLIW SIMD
// Registers r0 contains "a", r1 contains "b"// Value is returned in r2v_cmp_gt_f32 r0,r1 //a > b, establish VCCs_mov_b64 s0,exec //Save current exec masks_and_b64 exec,vcc,exec //Do "if"s_cbranch_vccz label0 //Branch if all lanes failv_sub_f32 r2,r0,r1 //result = a - bv_mul_f32 r2,r2,r0 //result=result * a
s_andn2_b64 exec,s0,exec //Do "else" (s0 & !exec)s_cbranch_execz label1 //Branch if all lanes failv_sub_f32 r2,r1,r0 //result = b - av_mul_f32 r2,r2,r1 //result = result * b
s_mov_b64 exec,s0 //Restore exec mask
Đó là những gì mà AMD muốn thay thế VLIW bằng NGC .
Như vậy AMD thay thế VLIW bằng cái gì ? Họ thay thế bằng bộ xử lí vector SIMD truyền thống . Bộ phận vector này là sự kết hợp của 64KB file thanh ghi ( Register File ) với một SIMD .
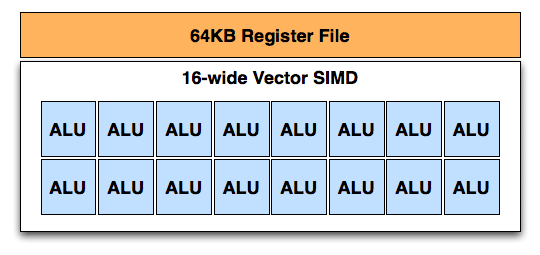
SIMD trong NGC có độ rộng 16 ( 16-wide ) có nghĩa là một lệnh và lên tới 16 thành phần dữ liệu được cung cấp tới SIMD để xử lí trong mỗi chu kì đồng hồ . Nhiều SIMD để tạo thành Compute Unit ( CU ) .
Compute Unit được AMD xem như là bộ phận cơ bản trong tính toán . Tại đây một SIMD có thể thực hiện những hoạt động thông thường và kết hợp với một số bộ phận chức năng khác để tạo thành bộ phận hoàn chỉnh để thực hiện những nhiệm vụ tính toán khác không chỉ riêng phục vụ công việc tính toán đồ họa .
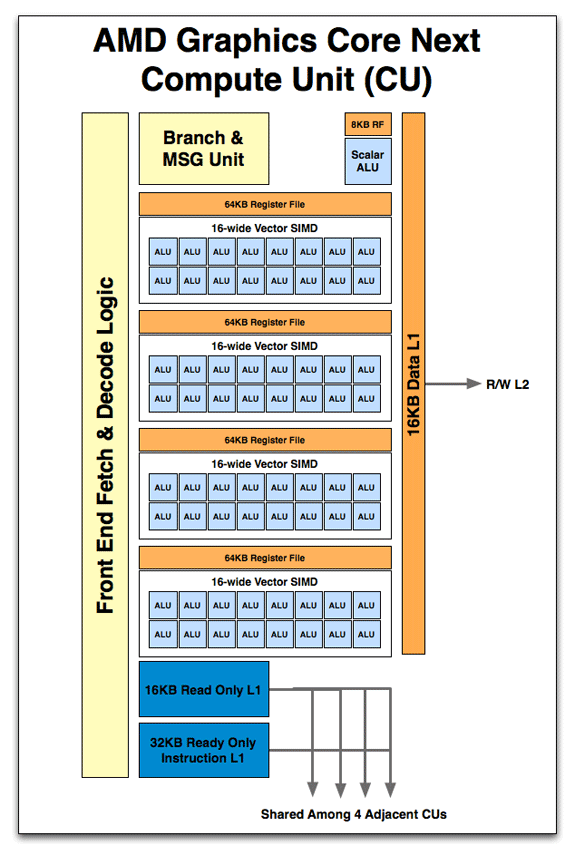
Nhiều Compute Unit để tạo thành một GPU
Trong cấu trúc lõi đồ họa mới NGC thành phần cơ bản là Compute Unit được thiết kế theo kiểu module kết hợp lại với nhau để tạo thành GPU hoàn chỉnh
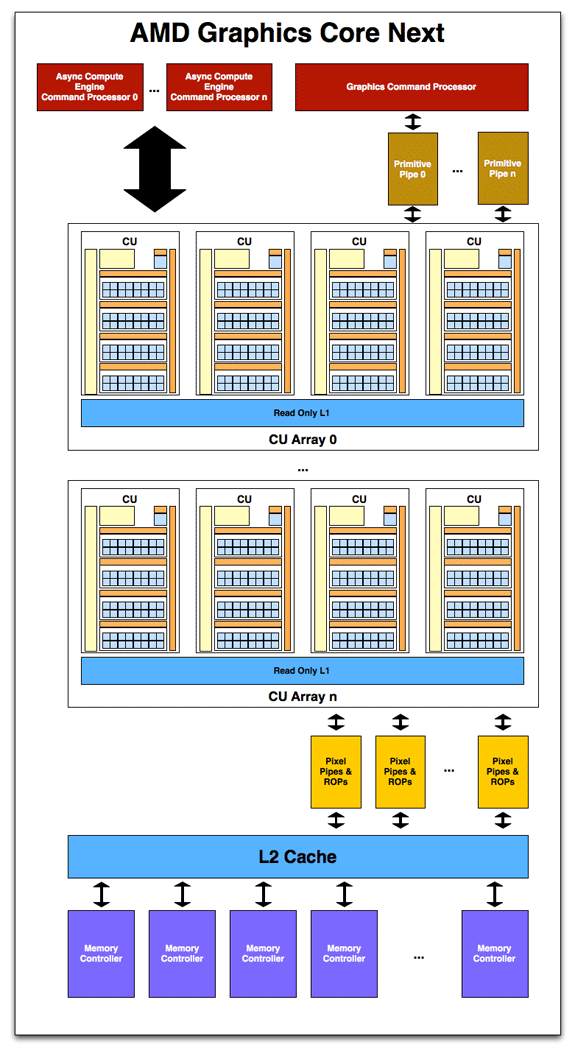
NGC có chứa bộ nhớ Cache L2 với mạch điều khiển bộ nhớ của nó . Cấu trúc này hỗ trợ 64KB hoặc 128GB Cache L2 cho mỗi mạch điều khiển bộ nhớ và những mạch điều khiển bộ nhớ AMD thông thường có độ rộng 64-bit .
Bộ nhớ Cache L2 là Write-Back được liên kết chặt chẽ với các Compute Unit để có thể xử lí cùng dữ liệu , không mất thời gian đồng bộ .
Trong cấu trúc mới có ACE (Asynchronous Compute Engines ) hoạt động như là những bộ xử lí lệnh cho những hoạt động tính toán trong NGC . Mục đích chủ yếu của ACE là lấy về và gửi dữ liệu đi tới các Compute Unit xử lí . NGC được thiết kế để làm việc đồng thời những nhiệm vụ khác nhau nên có thể nhiều ACE bên trong GPU . ACE quyết định vị trí nguồn tài nguyên , mức độ ưu tiên nhiệm vụ ….
Nói tóm lại những ACE trong NGC có những khả năng hạn chế của OOO ( Out-of-Order ) , như đang dùng trong những CPU , và cấu trúc GPU trước kia là theo thứ tự lệnh ( In-Order ) . Tuy nhiên ACE có thể ưu tiên hoặc đặt lại mức độ ưu tiên cho những nhiệm vụ cho phép những công việc được hoàn thành theo thứ tự khác nhau không phải một cách tuần tự thông thường .
Như vậy chúng ta có thể đơn giản hóa NGC có nghĩa là vẫn hoạt động tốt trong các ứng dụng tính toán đồ họa nhưng lại có khả năng thực hiện tốt những nhiệm vụ tính toán khác phục vụ cho các ứng dụng thông thường mà trước đây cấu trúc VLIW không đáp ứng được .
NGC không chỉ là cấu trúc mới mà còn có những tính năng mới
Một sự thay đổi lớn nhất chính là NGC hỗ trợ C++ và các ngôn ngữ tiên tiến khác . Như vậy NGC sẽ có thêm hỗ trợ cho những Con trỏ , những hàm ảo , đệ quy … Điều đó cho phép những nhà lập trình thông thường dễ dàng xây dựng các ứng dụng phức tạp tăng tốc dựa trên GPU . Tuy nhiên ngay lập tức người dùng cuối cùng chưa thể hưởng những lợi ích từ cấu trúc mới này vì cần có thời gian để đưa ra các ứng dụng phù hợp .
Hệ thống quản lí bộ nhớ và bộ nhớ cũng được cải tiến . Sự thay đổi chủ yếu ở đây chính là việc dùng bộ nhớ hợp nhất để trao đổi dữ liệu một cách dễ dàng giữa CPU với GPU .Với bộ nhớ , AMD thêm hỗ trợ ECC để bảo đảm độ toàn vẹn trong việc truyền dữ liệu của bộ nhớ qua Bus GDDR5 . Cả bộ nhớ SDRAM và VRAM có thể được ECC bảo vệ .
Những tính năng mới của cấu trúc NGC sẽ được AMD công bố khi mà họ chính thức phát hành những GPU loại này .
Tuy nhiên có điều chắc chắn rằng Trinity , là những APU Bulldozer 2012 , sẽ không dùng NGC bởi vì nó vẫn dựa trên cấu trúc VLIW4 . Liệu AMD có Card màn hình cao cấp dựa trên cấu trúc mới trong năm 2012 hay không ?
Một điều lưu ý đó là NVIDIA đã có những bước đi theo chiều hướng này trong cấu trúc Fermi trước AMD . NVIDIA đã tạo ra GPU tốt cho tính toán đồ họa và tốt cho những công việc tính toán thông thường nên hướng đi của NVIDIA được cho là đúng .